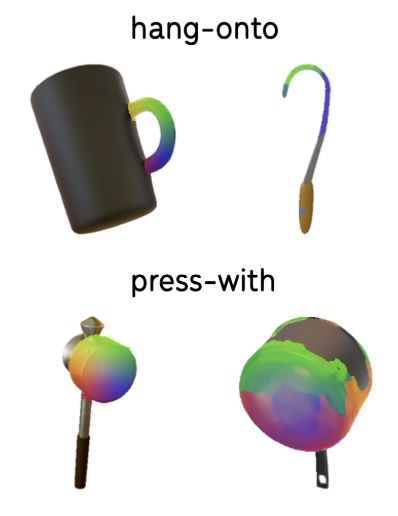Stefan Stojanov
stojanov@stanford.edu
![]()
![]()
![]()
![]()
![]()
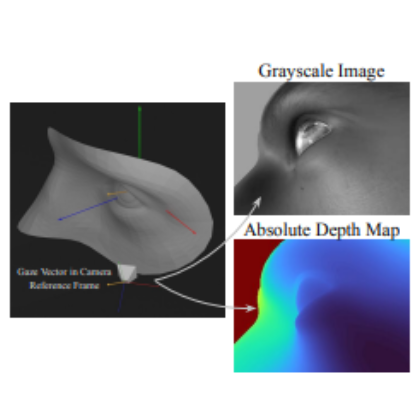
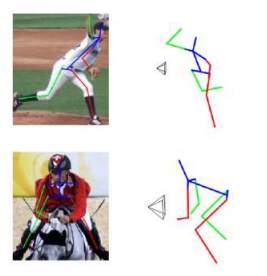
I am currently a research scientist at Google. Previously I was a postdoctoral researcher in the Stanford Vision and Learning Lab and Stanford NeuroAILab, advised by Jiajun Wu and Dan Yamins. At Stanford, I worked on developing video foundation models and fine-grained object representations. I was fortunate to be supported by a fellowship from Stanford HAI. I received my PhD at the Georgia Institute of Technology advised by James Rehg, where I worked on continual, self-supervised and low-shot learning, and 3D object shape reconstruction.